Rows: 58502 Columns: 25
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): WWTP_NAME, COUNTRY, CNTRY_ISO, STATUS, LEVEL
dbl (20): WASTE_ID, SOURCE, ORG_ID, LAT_WWTP, LON_WWTP, QUAL_LOC, LAT_OUT, L...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
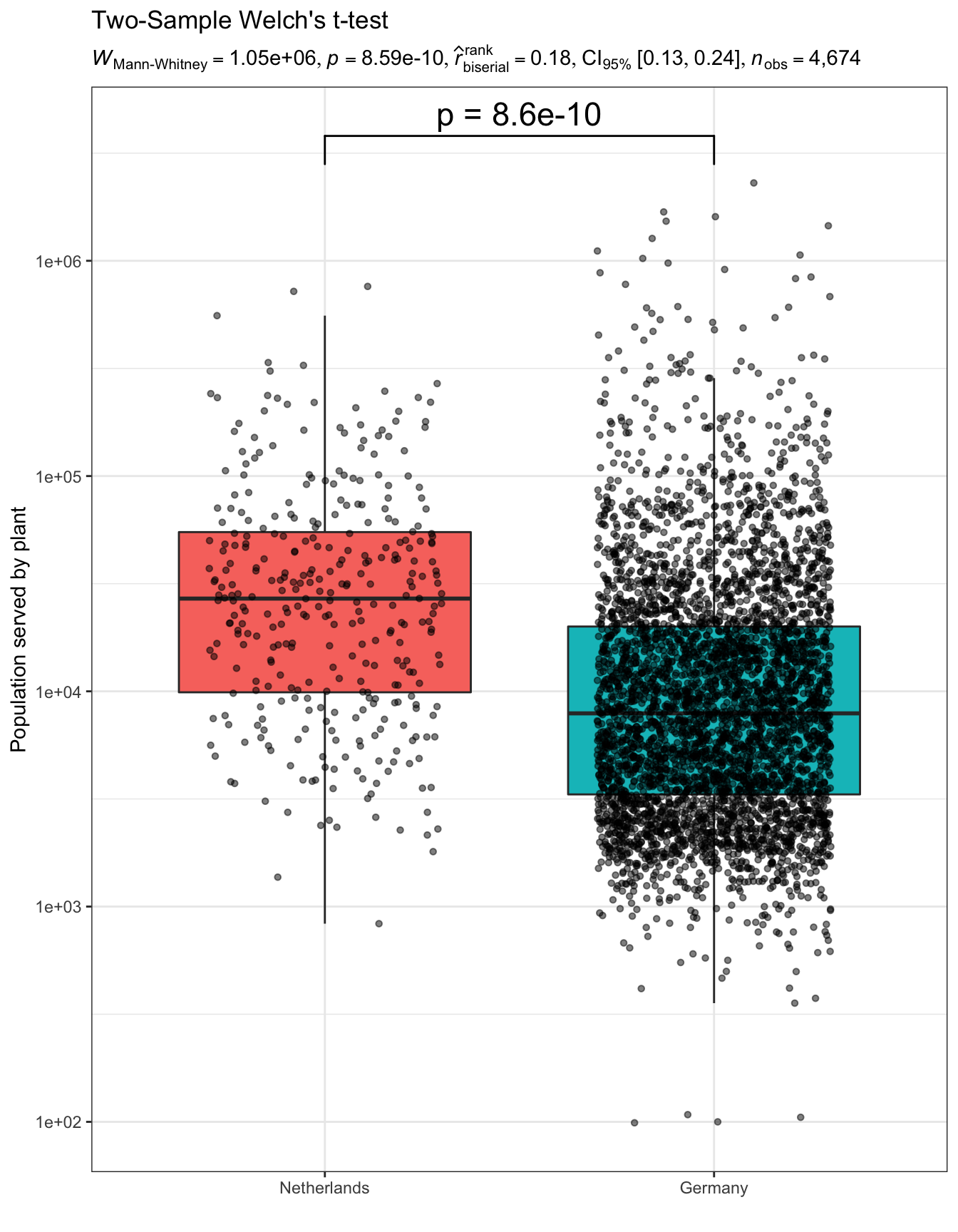
test_result<-statsExpressions::two_sample_test(waste_pairs, COUNTRY, POP_SERVED, type ="nonparametric")ggplot(waste_pairs)+aes(x =COUNTRY, y=POP_SERVED, fill =COUNTRY)+geom_boxplot(outlier.shape =NA)+geom_jitter(width =0.3, alpha =0.5, size =1.2)+ggsignif::geom_signif( comparisons =list(c("Netherlands", "Germany")),# map_signif_level = TRUE, map_signif_level = \(p)sprintf("p = %.2g", p), textsize =6, test ="wilcox.test")+labs( title ="Two-Sample Welch's t-test", subtitle =parse(text =test_result$expression), x ="", y ="Population served by plant")+theme_bw()+theme( legend.position ="none")+scale_y_log10()
Figure 2: Comparisons between German and Dutch population benefited from waste water plants
Some conclusions
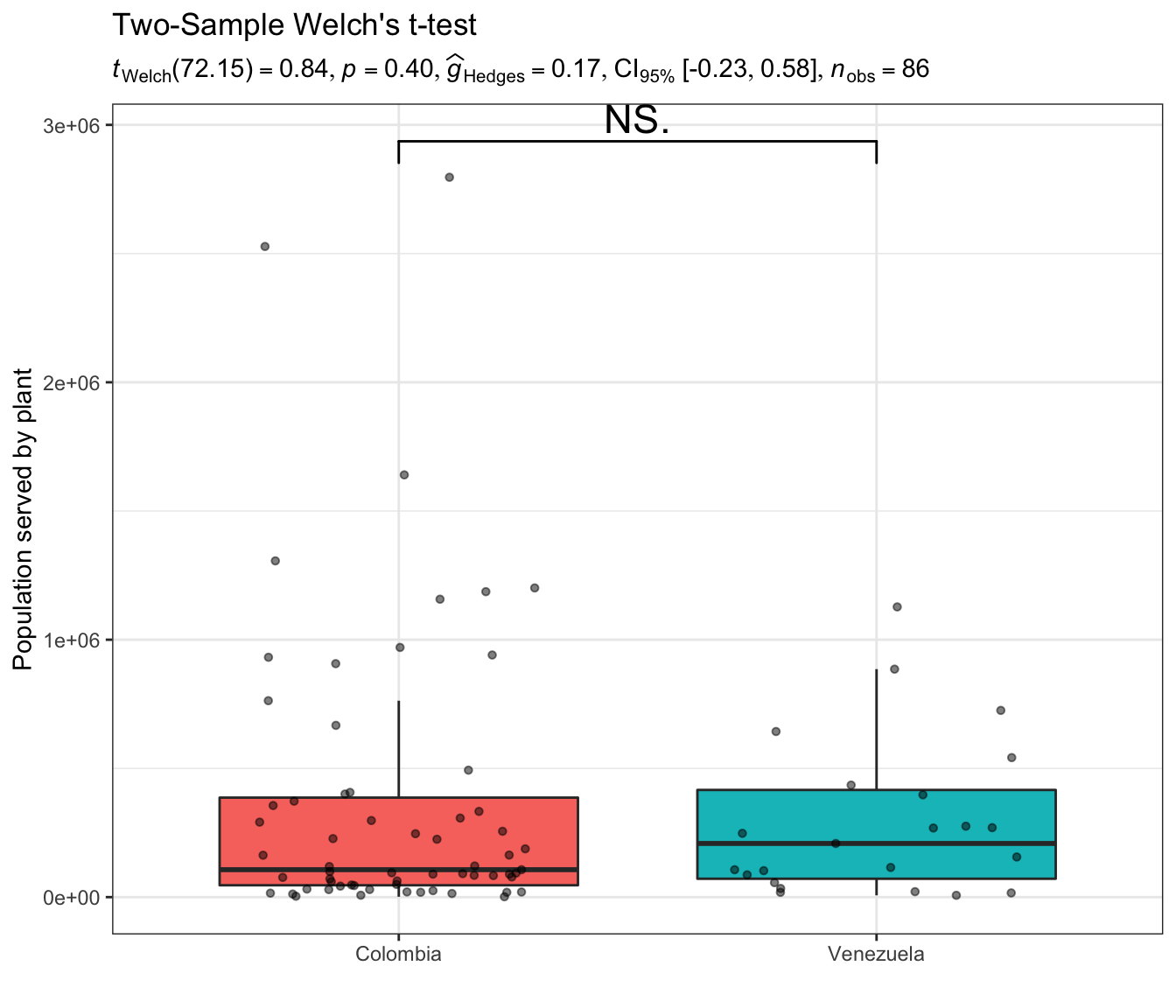
From the comparison between Colombia vs Venezuela benefited population from waste water plants Fig. 1, there are at least two important highlights. First, both countries display relatively low numbers plants given their extensions (this is something more of an intuition coming from the other comparisons as well), and a second thing is that there is actually no differences regarding the population they are attending. The opposite happens when comparing Germany vs. Netherlands benefited populations Fig. 2.
Citation
BibTeX citation:
@misc{garcía-botero2021,
author = {García-Botero, Camilo},
title = {Population Benefited from Waste Water Plants},
date = {2021-09-20},
url = {https://camilogarciabotero.github.io/blog},
langid = {en}
}