new_mean <- function(x) {
sum(x) / length(x)
}Descriptive Stats & Distributions
http://tinyurl.com/4dfuycvt

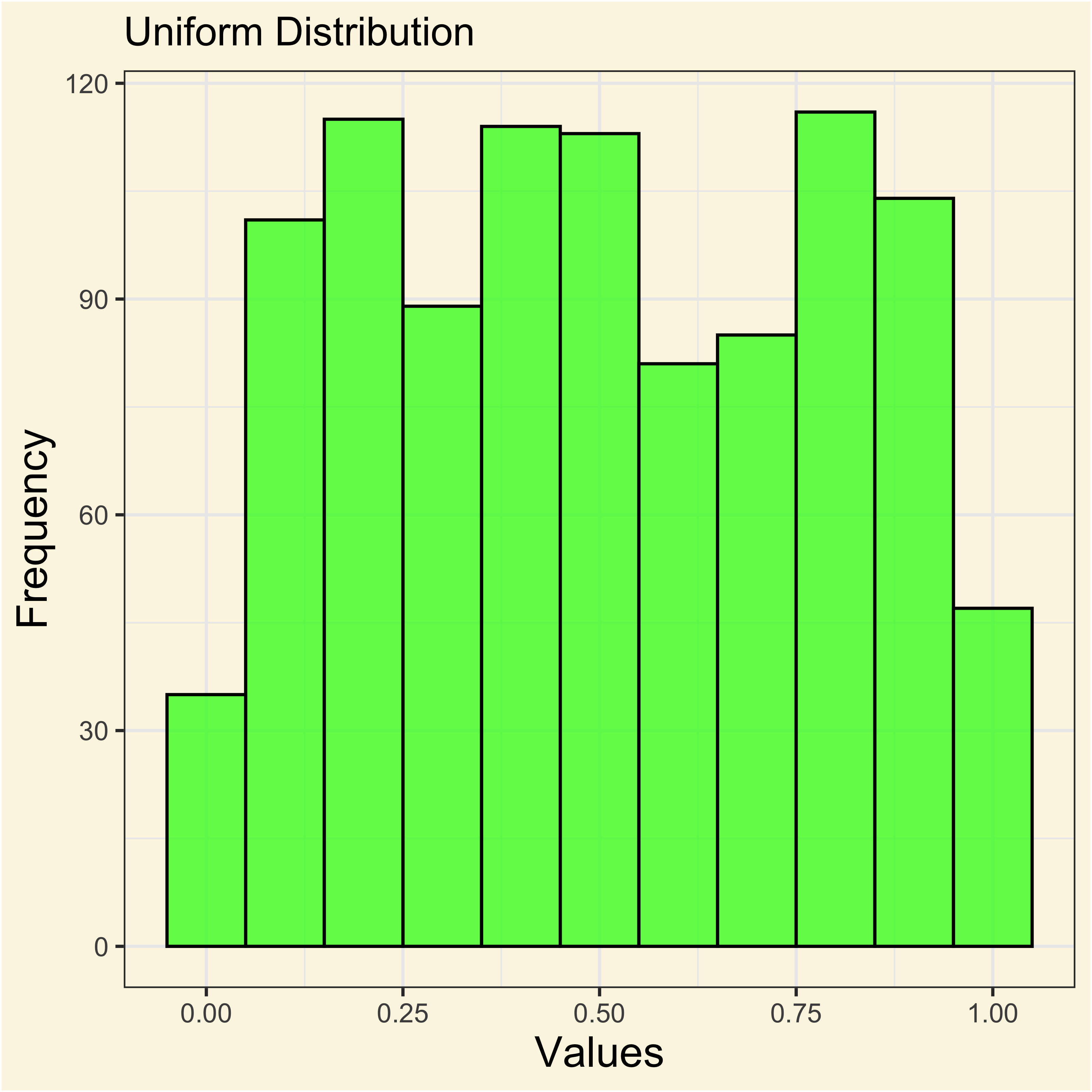
dfuniform <- runif(1000, min = 0, max = 1)
ggplot(data.frame(x = dfuniform), aes(x)) +
geom_histogram(
binwidth = 0.1,
fill = "green",
color = "black",
alpha = 0.7
) +
labs(
title = "Uniform Distribution",
x = "Values",
y = "Frequency"
)
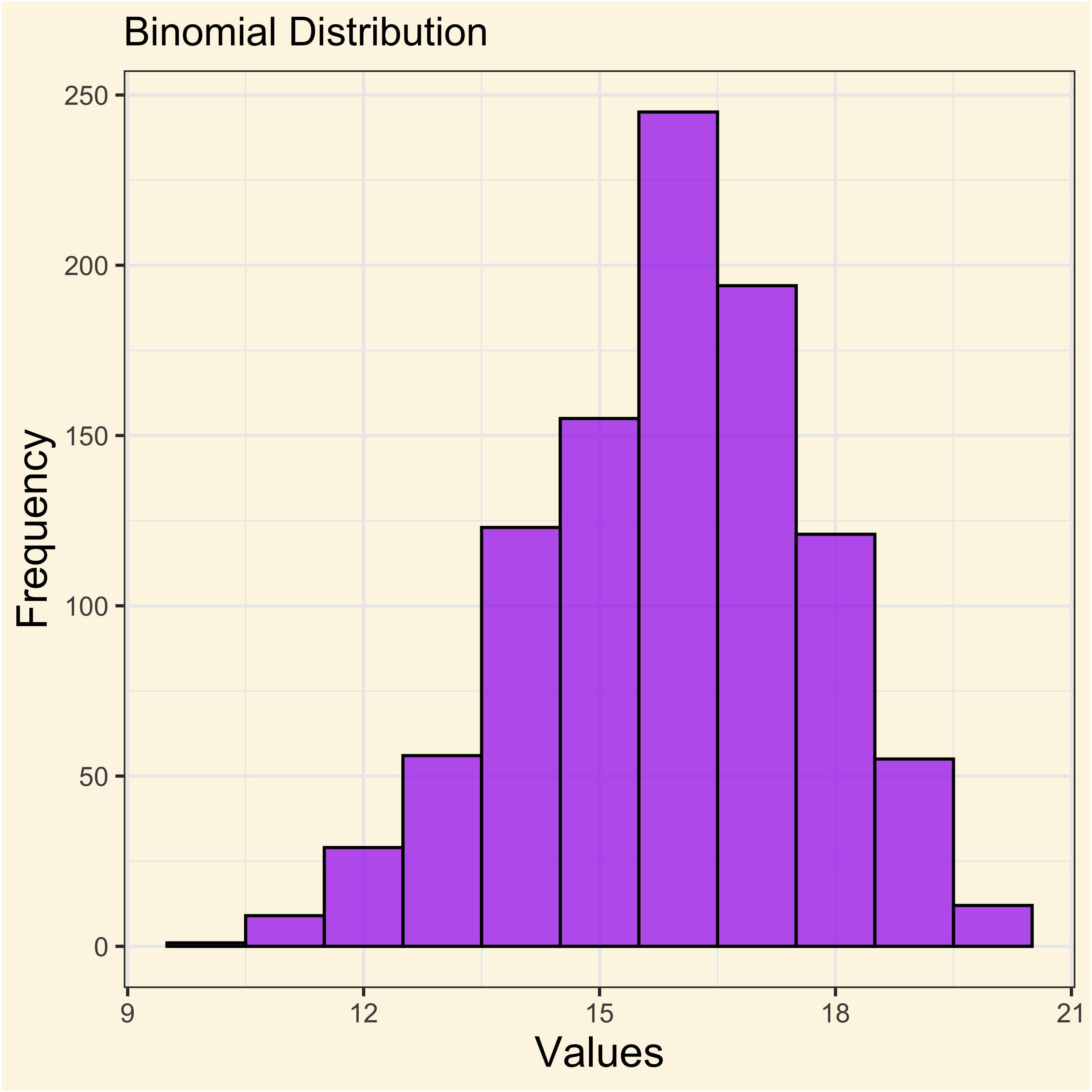
dfbin <- rbinom(1000, size = 20, prob = 0.8)
ggplot(data.frame(x = dfbin), aes(x)) +
geom_histogram(
binwidth = 1,
fill = "purple",
color = "black",
alpha = 0.7
) +
labs(
title = "Binomial Distribution",
x = "Values",
y = "Frequency"
)
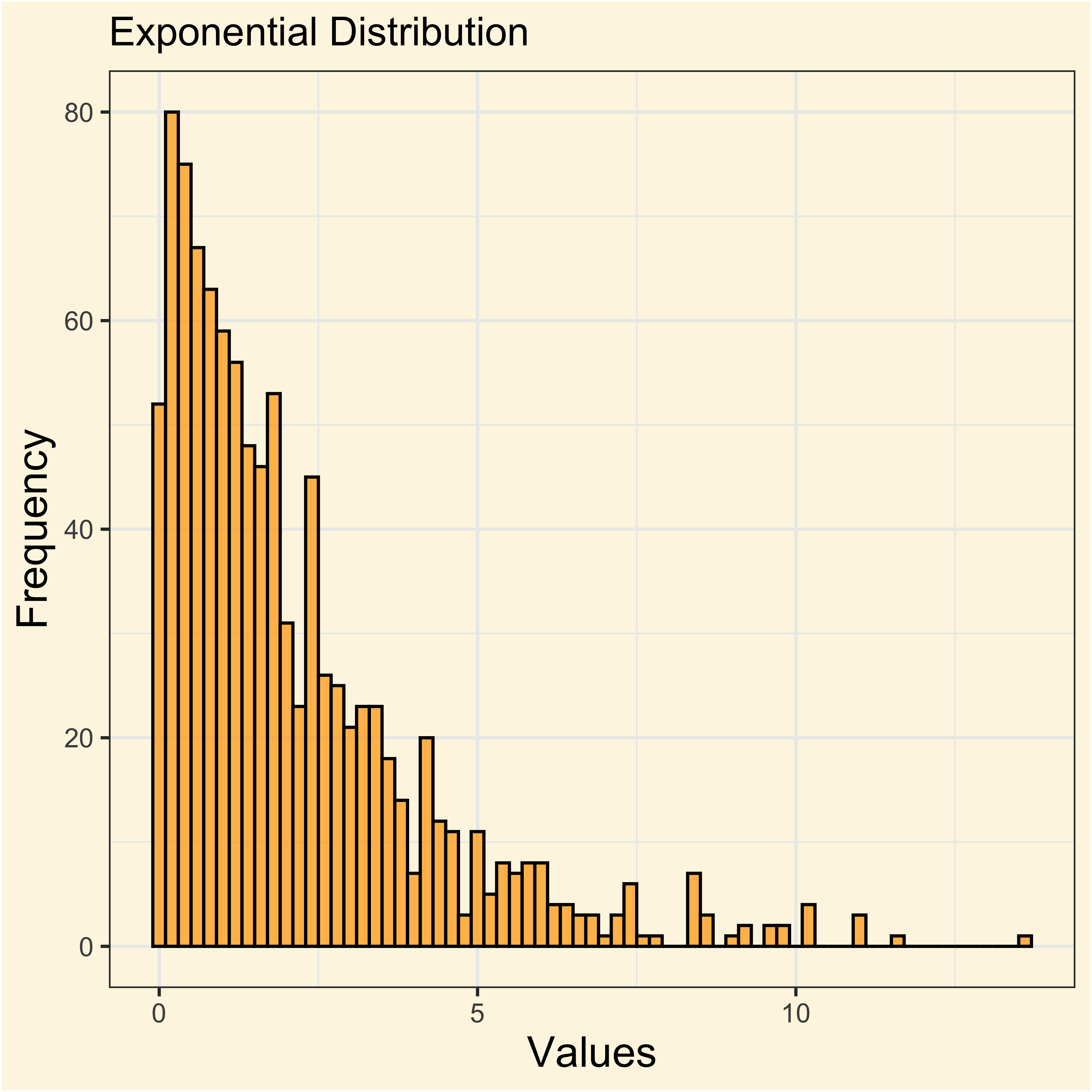
dfexp <- rexp(1000, rate = 0.5)
ggplot(data.frame(x = dfexp), aes(x)) +
geom_histogram(
binwidth = 0.2,
fill = "orange",
color = "black",
alpha = 0.7
) +
labs(
title = "Exponential Distribution",
x = "Values",
y = "Frequency"
)
dfnormal <- rnorm(1000, mean = 0, sd = 1)
ggplot(data.frame(x = dfnormal), aes(x)) +
geom_histogram(
binwidth = 0.2,
fill = "blue",
color = "black",
alpha = 0.7
) +
labs(
title = "Normal Distribution",
x = "Values",
y = "Frequency"
)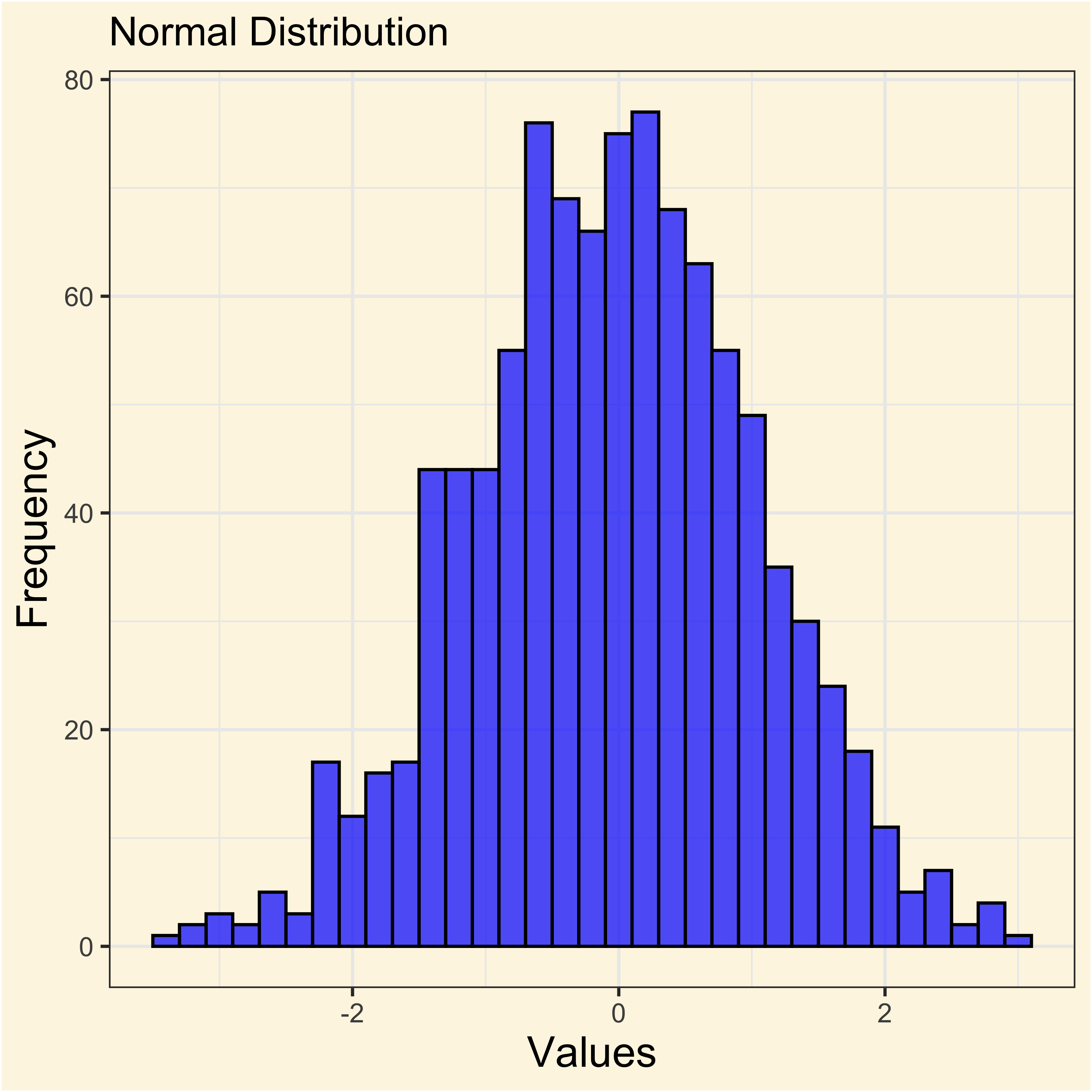
The standard normal distribution
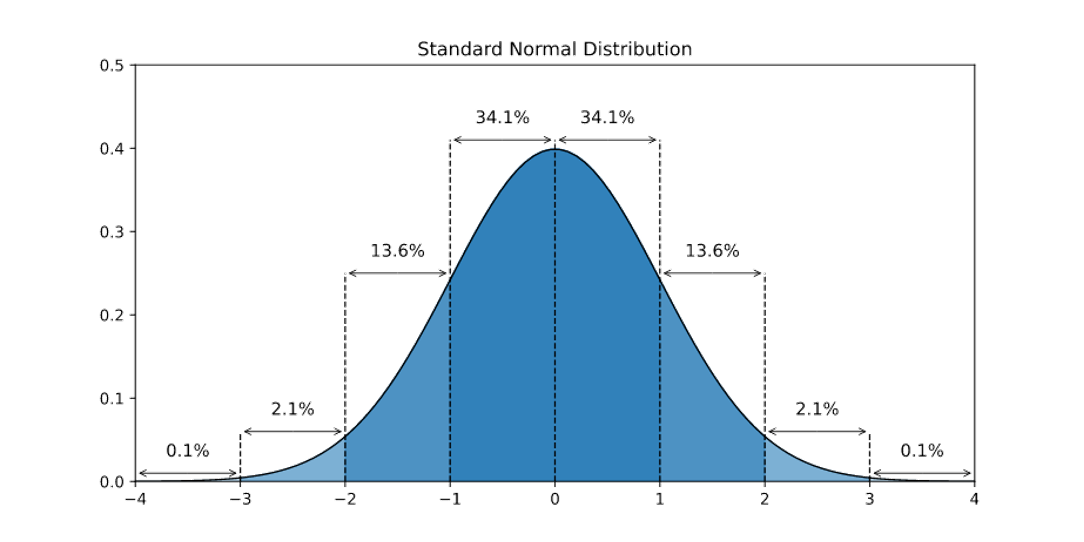
Where \(z = \frac{x - \mu} {\sigma}\) is the standardization function, the result is that \(\sigma = 1\) and \(\mu = 0\)
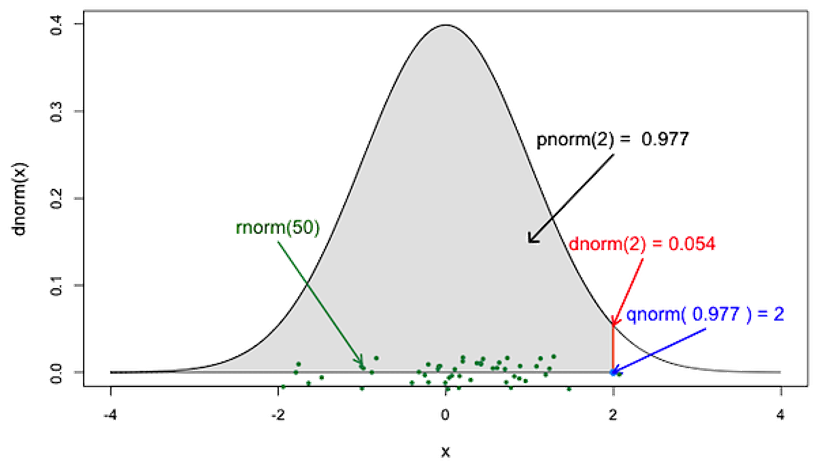
rnorm()generates pseudorandom normal numbers.dnorm()is the probability density function (PDF)pnorm()is the cumulative density functionqnorm()calculates the quantile of the normal distribution